
Recently, there has been a lot of excitement and interest around circle STARKs. This didn't pass me by either, and my interest was piqued. Not only by the loud "breakthrough" announcements and the prospects of unlocking verifiable computation on Bitcoin, but also by the subtle elegance of applied algebraic geometry to address limitations and simplify previous solutions.
At this point, we have several excellent introductory and explainer articles by zkSecurity, Vitalik, and LambdaClass. I have tried my best not to repeat their words and instead focus on the unexplored aspects and elements that I personally found very interesting. I wrote this as I was learning, so I cannot rule out inaccuracies. If you spot any mistakes, please comment away in this mirror on HackMD.
Introduction
Circle STARKs enable the prover to work over the finite field modulo Mersenne 31 prime (M31), which has very efficient arithmetic. Namely, it is 1.3 times faster than BabyBear, the previous most efficient field used in SP1, Valida, and RISC Zero. For more insight on why working over M31 is so desirable, refer to this article.
However, simply plugging M31 into existing univariate STARKs won't work. The reason is that Mersenne primes are not FFT/FRI friendly. Let's unpack why.
The efficiency of the FFT "divide-and-conquer" algorithm relies on the ability to recursively divide the problem size by powers of 2. When working over a finite field, this requirement necessitates an evaluation domain to have the "structure" of a multiplicative group whose order's factorization contains a large power of two. We refer to this as high 2-adicity. The reason we want this is that at each step of the FFT, we reduce the size of the domain by a factor of two by squaring each number in it.
For example, consider the domain in the finite field of integers modulo . This domain forms a multiplicative group with elements. The elements of this group are powers of , which is a generator of the group. If you square every number in the domain, you reduce the size of the domain by a factor of two: . If you take the same domain but with, say, 6 elements, you don't get this property anymore.
Another relevant way of framing the 2-adicity requirement is to search for a group whose order is a product of small primes. We call such numbers smooth numbers. Since the multiplicative group of a field includes every element except , the order of the group is exactly one less than the number of elements in the field. Fields that satisfy this condition are referred to as smooth.
An exemplary prime is the BabyBear prime . The largest multiplicative group in the BabyBear field has elements. You can clearly see that it is both smooth and highly 2-adic. It's perfect.
What about the Mersenne-31 prime ? Unfortunately, can be divided by 2 only once. Thus, the conventional Cooley-Tukey FFT algorithm would be very inefficient for this field group. The authors solve this by devising a group from a unit circle.
Circle as a group
A circle group is generated from a point such that (i.e., it lies on a unit circle) by applying a different multiplicative law:
Instead of generating subgroup elements as simply powers of a generator , we move from a point on the circle to the point:
It turns out that the number of points lying on the circle, defined over the Mersenne prime , is quite large (). One can generate all group elements by starting with and applying the generator using the law above.
For the circle FFT/FRI, we need two more group operations: the group squaring map and the inversion map .
Squaring is the quadratic map defined as
This transformation reduces the set size by half.
Inverse is given by the degree-one map
This operation maps each point to its reflection .
Map is an involution, i.e., . Maps and commute, i.e., for every .
FFT over the circle domain
Same as in the classical STARK, the circle FFT is used to evaluate some polynomial on a special domain. In regular FFT, the domain consists of -th roots of unity, i.e. . In circle FFT, the domain is a set of points on a circle curve, generated as follows.
First, we take a circle group generator and square it times to create a subgroup . Then, we create two twin cosets, which are formed by taking an element that is not in and creating two disjoint sets: and . The union of these sets forms the circle FFT domain containing elements. A self-descriptive implementation can be found here in Plonky3.
An interactive plotter to demonstrate the distribution of domain points, which uses a simple TS implementation of the circle group over Mersenne-17 field. Even though it's modulo prime p, you can still see a regular circular patterns with symmetry about the line p/2. This phenomena is also exists in elliptic curves (genus 1), but is much more apparent on circle curves (genus 0) and complex roots of unity.
The FFT works by recursively splitting the larger problem into two smaller ones. In the context of polynomial evaluation, this means decomposing the polynomial into "even" and "odd" parts. In regular FFT, these sub-polynomials are simply formed from even and odd coefficients of the original polynomial. In circle FFT, this is a bit more involved, as we'll see, but the underlying mechanics is the same — the original polynomial is a linear combination . At each split, we also reduce the domain by a factor of two.
In the first step, we "halve" the domain by simply taking an projection of each point. This is justified by the use of the inverse map when performing a decomposition such that:
I have modified the notation to demonstrate how in practice we treat polynomials as vectors of their coefficients. Compare the original notation here with Vitalik's implementation here.
You can think of the inverse map as a way to identify vertically mirrored pairs of points so that they can be treated as a single entity. This allows us to proceed with only the coordinate.
In later steps, we continue to halve the domain using the univariate squaring map . This is analogous to squaring the -th root of unity such that . The even-odd decomposition (in the original notation) — now looks like this:
Although speeding up the FFT is not the main point of the paper, as author points out here, it serves as an effective demonstration of the core principles of working over the circle group. When studying the paper, I made the mistake of skipping it and rushing to circle FRI only to hit a wall of confusion. So, I encourage you to take some time to appreciate this mechanic. If you want to play around with it, I made this Python notebook (trigger warning: shitty code).
Regular FRI
Structure of the FRI algorithm is a lot like FFT. But instead of recursively dividing the polynomial into many smaller ones, in FRI, the prover iteratively reduces the degree of a polynomial until it gets to some small constant-size one. It does so via random linear combination, i.e., by combining "even" and "odd" sub-polynomials against a random weight.
In STARK, we use FRI for something called "low-degree testing"—by knowing the final degree and the number of reduction steps, the verifier can work backwards and check that the degree bound of the original polynomial is as claimed. More formally, FRI enables an untrusted prover to convince a verifier that a committed vector is close to a Reed-Solomon codeword of degree over the domain .
Here, being "close" is defined by the relative Hamming distance such that the number of points where the committed vector and the codeword disagree is at most . The distance is such that where is the rate of the Reed-Solomon code. In turn, the rate is defined by the blow-up factor so that . Finally, the domain size is where is the size of the original vector.
To make this definition more senseful, let's assign standard values: A commonly used blow-up factor is , so the rate is . The worst possible distance is , so for a vector with 1024 elements, the codeword over a sized domain can disagree on at most half of the points. In practice, is much smaller to give better soundness guarantees.
Another interesting property is the decoding regime. In the unique decoding regime, the goal is to identify a single low-degree polynomial that is close to the committed vector. The unique decoding radius is typically defined as: .
STARKs are shown to be sound outside this regime as the goal is to demonstrate the existence of such polynomials, even if multiple polynomials fit the given points. We refer to this simplified requirement as the list decoding regime. The list decoding radius is typically defined as: . HAB23
Circle FRI
The general mechanics behind low-degree testing over the circle domain remain unchanged from the regular FRI. As a reminder, see this blog post for an in-depth theoretical discussion or this one if you only care about the implementation.
Circle FRI operates on codewords in the circle code , which is a generalization of the Reed-Solomon code defined over elements of the circle group and special polynomials in Riemann-Roch space. Oversimplified, they are bivariate polynomials modulo the unit circle equation , so whenever a polynomial has , it's replaced by .
For a given proximity parameter , the interactive oracle proof of a function (mapping the committed vector) being -close to the circle codeword consists of rounds of a commit phase and a subsequent query phase, which are as follows.
Commit phase
- decomposes into and sends to
- picks random weight for layer
- For each , decomposes into "even" and "odd" parts; sends a commitment to
- In the last round, sends in plain.
1. decomposes into and sends to
We start with the extended domain coset . First, we want to find the component of that is aligned with . This can be done using vector projection: given two functions (or vectors) and , the projection of onto is given by:
Note: angle brackets denote the inner product .
Taking as the magnitude of this projection will ensure that is the part of that lies along
The vanishing polynomial has an alternating behavior over the domain , e.g., if has size , then alternates as . This significantly simplifies the inner product calculations as , each term so
Knowing , we can now find , which represents the component of that is orthogonal to
This ensures that lies entirely in the FFT space , orthogonal to . This is because the inner product , making and orthogonal by construction.

2. picks random weight for layer
In practice, though, can compute as a random linear accumulator starting with and using a single random weight picked by
See this done in Stwo.
3. For each , decomposes into "even" and "odd" parts
The "even-odd" decomposition follows the same progression as in FFT. In the first round, we work with 2D points and use the full squaring and inverse maps. The inverse map transformation allows us to identify points and their reflection so we can treat them as a single point on the -axis in subsequent rounds. The squaring map transforms the domain into by effectively halving the space of points:
where and is a twiddle factor. Then, fold into a random linear combination against :
Commitment is a simple Merkle root. Under the Fiat-Shamir transformation, also sends openings, i.e., Merkle branches for FRI queries.
Query phase
1. samples queries uniformly from the domain
For each query , considers its "trace" as the sequence of points obtained by repeatedly applying the squaring map and the transformations defined by the protocol. The initial query point is transformed through several rounds, resulting in a series of points in different domains :
2. For each , asks for the values of the function at a query point and its reflection
Given the commitment , as in oracle access, can ask the oracle for the values (openings) at query points. In other words, verify Merkle proofs at the points:
where at , and for , .
3. checks that the returned values match the expected values according to the folding rules
This involves checking that the even and odd decompositions are correct and that the random linear combinations used to form from are consistent.
DEEP quotients
Quotienting is the fundamental polynomial identity check used in STARK and PLONKish systems. Leveraging the polynomial remainder theorem, it allows one to prove the value of a polynomial at a given point. Vitalik's overview of quotienting is well on point, so I will focus on the DEEP-FRI over the circle group.
DEEP (Domain Extension for Eliminating Pretenders) is a method for checking consistency between two polynomials by sampling a random point from a large domain. In layman's terms, it lets FRI be secure with fewer Merkle branches.
In STARK, we use the DEEP method on a relation between the constraint composition polynomial (one that combines all the constraints) and the trace column polynomials, all evaluated on a random point . For more context, see this post and the ethSTARK paper.
The first part is DEEP algebraic linking: It allows us to reduce the STARK circuit satisfiability checks (for many columns and many constraints) to a low-degree test (FRI) on single-point quotients. By itself, DEEP-ALI is insecure because the prover can cheat and send inconsistent evaluations on . We fix this with another instance of quotienting—DEEP quotienting.
We construct DEEP quotients with a single-point vanishing function in the denominator to show that a certain polynomial, say a trace column , evaluates to the claim at , i.e., .
In classical STARKs, is simply a line function . In circle STARKs, in addition to not having line functions, we also run into the problem that single-point (or any odd degree) vanishing polynomials don't exist. To get around this, we move to the complex extension, i.e., decomposing into real and imaginary parts
Using with this quirk, we follow the standard procedure constructing a composite DEEP quotient polynomial as a random linear combination. We use different random weights for the real and imaginary parts
In the ethSTARK paper, the prover does batching using random weights provided by the verifier (affine batching). Here, the prover uses powers of a single random weight (parametric batching).
Computing naïvely will suffer overhead due to the complex extension, essentially doubling the work due to real and imaginary decompositions. The authors solve this by exploiting the linearity in the above equation. The prover now computes
where and .
Interestingly, Stwo and Plonky3 actually use different quotienting approaches: Plonky3 implements the method described in the paper and here, but Stwo chooses instead to use a 2-point vanishing polynomial, as described in Vitalik's note.
Field work
In circle STARK, work is done over the finite field and its extension where is the extension degree. For , we choose M31, but any other smooth prime will suffice. The extension field used in Stwo and Plonky3 is QM31, a degree-4 extension of M31, aka. the secure field.
In rare cases, it will be useful to work with the complex extension , the field that results from by extending it with the imaginary unit . Note that may trivially be contained in some fields, e.g., if then in is both and (since ). For those fields where this isn't the case, such as , we can devise a quadratic extension, , which extends the original field in the same way complex numbers extend rationals.
A more common notation is , which means forming a field extension where . This results in a new field with elements of the form where and is a root of , such that .
- Trace values are over the base field and trace domain are points over the base field .
- The evaluation domain consists of points over the base field .
- All random challenges and weights for linear combinations are drawn from the secure field.
- When computing DEEP quotients, we move from the base field to secure fields, while briefly using complex extensions for vanishing denominators.
- Circle FRI works mainly on the secure field. However, query values are base field elements since we Merkle commit to values in the base field.
The results
That's cool and all, but let's see how all this translates into actual performance differences. Below I have profiling charts comparing Plonky3 with regular STARK over BabyBear and circle STARK over M31.
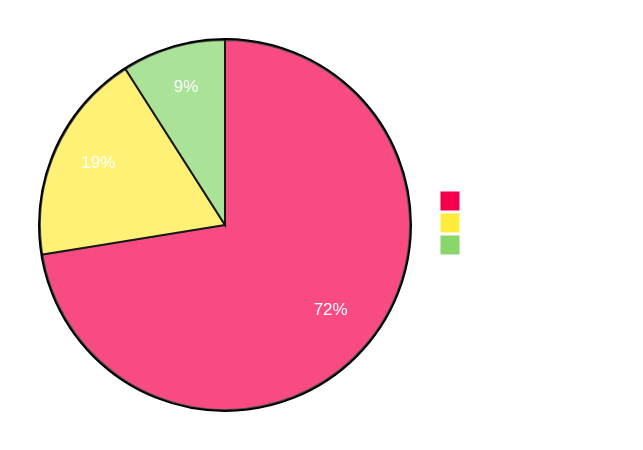
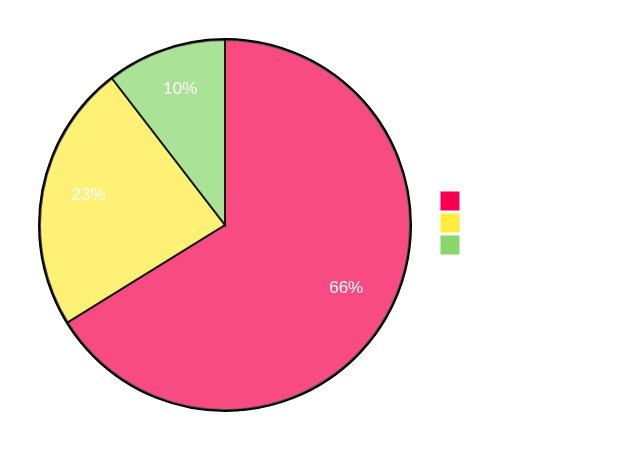
The first thing to note is that the difference in prover time is indeed about 1.3x. You can see that circle STARK spends less time committing to the trace, as it does so over a more efficient base field. Consequently, since computing quotients and FRI involves extension field work, these are now account for a larger percentage of the total work.
Thanks to Shahar Papini for feedback and discussion.
References
- [HLP24] Haböck et al. (2024) "Circle STARKs"
- [HAB23] Ulrich Haböck (2023) "A summary on the FRI low degree test"
- [ethSTARK] StarkWare Team (2023) "ethSTARK Documentation — Version 1.2"

